¿Qué es el Overfitting?
El overfitting, o sobreajuste, es un problema en el aprendizaje automático que ocurre cuando un modelo aprende demasiado bien los datos de entrenamiento, incluyendo patrones irrelevantes o ruido. Esto provoca que el modelo tenga un rendimiento excelente en los datos con los que fue entrenado, pero que falle al enfrentarse a nuevos datos, ya que no logra generalizar. En lugar de captar la estructura subyacente de los datos, el modelo memoriza casos específicos. El overfitting es común cuando se utilizan modelos muy complejos con pocos datos. También puede surgir al entrenar durante demasiadas épocas. Es un indicio de que el modelo está adaptado en exceso al conjunto de entrenamiento.
Causas Principales del Overfitting
Las principales causas del overfitting se relacionan con la complejidad del modelo y la calidad de los datos. Cuando un modelo tiene demasiados parámetros o capas para la cantidad de datos disponibles, tiende a aprender detalles irrelevantes. Otra causa frecuente es el uso conjunto de datos de entrenamiento pequeño o no representativo, lo que impide una buena generalización. También influye la presencia de ruido o errores en los datos, que el modelo puede interpretar como patrones reales. Un entrenamiento excesivo, sin mecanismos de control como validación o detención temprana, agrava el problema. Además, incluir sin mecanismos características irrelevantes o altamente correlacionadas puede incluir al modelo a ajustar patrones espurios.
Síntomas del Overfitting
Los síntomas del overfitting se manifiestan principalmente en la discrepancia entre el rendimiento del modelo en los datos de entrenamiento y en los de validación o prueba. Un modelo sobreajustado suele mostrar una precisión muy alta en el entrenamiento, pero baja en datos nuevos. Además, el error de validación aumenta mientras el de entrenamiento continúa disminuyendo, lo que indica que el modelo está dejando de generalizar. También puede observarse que el modelo es muy sensible a pequeñas variaciones en los datos. Otro signo es que realiza predicciones erráticas en situaciones no vistas.
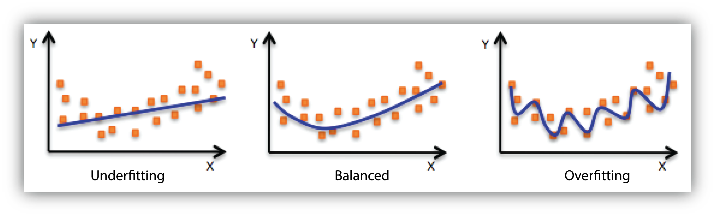
Overfitting vs. Underfitting
El overfitting y el underfitting son problemas opuestos en el entrenamiento de modelos de inteligencia artificial. El overfitting ocurre cuando el modelo aprende demasiado de los datos de entrenamiento, incluyendo el ruido, y no generaliza bien a datos nuevos. En cambio, el underfitting sucede cuando el modelo es demasiado simple para captar la complejidad de los datos, lo que provoca un mal rendimiento tanto en entrenamiento como en una prueba. Mientras que el overfitting se asocia con modelos complejos y sobreentrenados, el underfitting suele deberse a modelos básicos o mal configurados. El objetivo del aprendizaje automático es encontrar un equilibrio entre ambos extremos. Detectar estos problemas requiere comparar errores de entrenamiento y validación.
Ejemplos Comunes de Overfitting
Existen varios ejemplos comunes de overfitting en distintas áreas de la inteligencia artificial. En visión por computadora, un modelo puede aprender a reconocer detalles específicos de imágenes del conjunto de entrenamiento, como sombras o marcas, en lugar de las características generales, fallando al clasificar imágenes nuevas. En procesamiento de lenguaje natural, un modelo puede memorizar frases exactas sin entender su significado, generando respuestas incoherentes ante textos distintos. En predicción financiera, puede ajustar sus cálculos a movimientos pasados del mercado, pero sin adaptarse a condiciones futuras. También ocurre en sistemas de recomendación que siguieran productos basándose únicamente en patrones de usuarios anteriores, ignorando nuevos intereses.
Técnicas para Detectar el Overfitting
Para detectar el overfitting, se utilizan varias técnicas que permiten evaluar si un modelo está generalizando correctamente. Una de las más comunes es comparar el rendimiento del modelo en los datos de entrenamiento y de validación: si la precisión en entrenamiento es alta pero baja en validación, hay señales claras de sobreajuste. Las curvas de aprendizaje también ayudan, mostrando cómo evoluciona el error en ambos conjuntos a lo largo del entrenamiento. Otra técnica útil es la validación cruzada, que evalúa el modelo en múltiples particiones del conjunto de datos. Observar el comportamiento del error a medida que se entrena permite aplicar estrategias como el early stopping. También puede analizarse la sensibilidad del modelo a pequeños cambios en los datos. Detectar el overfitting a tiempo evita modelos ineficientes y poco confiables.
Métodos para Prevenir el Overfitting
Existen varios métodos efectivos para prevenir el overfitting en modelos de inteligencia artificial. Una de las técnicas más utilizadas es la regularización (como L1 o L2), que penaliza la complejidad del modelo reduciendo pesos innecesarios. El dropout, aplicado en redes neuronales, desactiva aleatoriamente algunas neuronas durante el entrenamiento para evitar la dependencia excesiva de ciertas rutas. También es útil el early stopping, que detiene el entrenamiento cuando el rendimiento en validación comienza a deteriorarse. Otra estrategia es aumentar la cantidad y calidad de los datos, mediante técnicas de data augmentation. La reducción de la dimensionalidad y la selección de características relevantes también contribuyen a mejorar la generalización. Combinar varias de estas técnicas suele ofrecer mejores resultados.
Importancia del Conjunto de Validación
El conjunto de validación es fundamental en el entrenamiento de modelos de inteligencia artificial, ya que permite evaluar su capacidad de generalización sin recurrir al conjunto de prueba final. Su principal función es medir el rendimiento del modelo durante el entrenamiento, ayudando a ajustar hiperparámetros y a detectar problemas como el overfitting. Si un modelo obtiene buenos resultados en entrenamiento pero falla en validación, es señal de sobreajuste. Además, técnicas como el early stopping dependen directamente del desempeño en este conjunto. Usar un conjunto de validación bien separado asegura una evaluación más realista. También permite comparar diferentes modelos y configuraciones antes de elegir el definitivo.
Perspectivas Futuras del Overfitting
Las perspectivas futuras del overfitting en inteligencia artificial apuntan a un desarrollo continuo de técnicas más avanzadas para su detección y prevención. A medida que los modelos se vuelven más complejos, especialmente con la llegada de redes neuronales profundas y modelos de gran escala, el riesgo de sobreajuste aumenta. Se espera que la combinación de inteligencia artificial explicable y nuevos métodos de regularización ayuden a entender mejor cómo y por qué ocurre el overfitting. También, el uso de grandes volúmenes de datos y aprendizaje automático basado en transferencias contribuirá a mejorar la generalización. Las herramientas automatizadas para ajustar hiperparámetros y evaluar modelos serán cada vez más sofisticadas. En el futuro, la colaboración entre humanos y máquinas facilitará la creación de modelos que eviten este problema.





