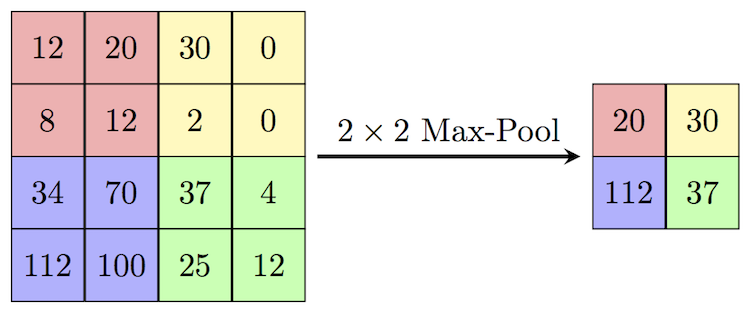
¿Qué es el Max Pooling?
El max pooling es una técnica utilizada en redes neuronales convolucionales para reducir la dimensión espacial de las imágenes o mapas de características. Consiste en dividir la entrada en pequeñas regiones o ventanas, y seleccionar el valor máximo dentro de cada una de ellas. Esto permite conservar la información más relevante y prominente, mientras se descartan valores menos importantes. Al reducir el tamaño de los datos, el max pooling ayuda a disminuir la complejidad y evita el sobreajuste. Además, aporta invarianza a pequeñas traslaciones o movimientos en la imagen. Es una operación clave para mejorar la eficiencia y robustez en tareas de visión en la imagen. Es una operación clave para mejorar la eficiencia y robustez en tareas de visión por computadora.
Funcionamiento del Max Pooling
El funcionamiento del max pooling se basa en aplicar una ventana deslizantes, generalmente de tamaño 2×2 o 3×3, sobre un mapa de características. Esta ventana se mueve por la imagen con un cierto paso (stride), y en cada región selecciona el valor más alto. El resultado es una nueva matriz de menor tamaño que conserva las características más destacadas. Por ejemplo, si una ventana cubre los valores [1, 3; 2, 4], el max pooling devolverá 4. Esta operación se repite por toda la imagen, generando una versión más compacta del modelo.
Objetivos del Max Pooling
El max pooling tiene como principal objetivo reducir la dimensión espacial de los mapas de características, manteniendo la información más importante. Al seleccionar solo el valor máximo de cada región, se conservan las señales más fuertes o activaciones más relevantes. Esto permite simplificar la representación de los datos sin perder las características esenciales. También contribuye a prevenir el sobreajuste al eliminar detalles irrelevantes. Además, el max pooling introduce cierta invarianza a pequeñas traslaciones en la imagen, mejorando la robustez del modelo.
Comparación con otras Técnicas de Pooling
El max pooling se compara comúnmente con otras técnicas de pooling, como el average pooling y el global pooling. Mientras el max pooling selecciona el valor más alto dentro de una región, el average pooling calcula el promedio de los valores. Esto hace que el max pooling resalte las características más fuertes, mientras que el average pooling toma un único valor representativo de toda la imagen, lo que es útil para reducir drásticamente la dimensionalidad antes de una capa totalmente conectada. Max pooling suele ser preferido cuando se busca conservar bordes y detalles de una capa totalmente conectada. Max pooling suele ser preferido cuando se busca conservar bordes y detalles prominentes. Sin embargo, en algunos casos, combinar técnicas puede mejorar el rendimiento.
Aplicaciones Comunes del Max Pooling
El max pooling se utiliza ampliamente en aplicaciones de visión por computadora dentro de redes neuronales convolucionales. Una de sus principales aplicaciones es la clasificación de imágenes, donde ayuda a identificar patrones visuales clave reduciendo la complejidad. También es esencial en la detección de objetos, permitiendo que el modelo enfoque su atención en las características más destacadas. En el reconocimiento facial, mejora la precisión al perseverar detalles relevantes como contornos y rasgos distintivos. Además, se emplea en sistemas de reconocimiento de texto en imágenes y en análisis de vídeo. Su eficiencia lo hace ideal para dispositivos con recursos limitados.
Ventajas del Max Pooling
El max pooling ofrece varias ventajas clave en redes neuronales convolucionales. Una de las más importantes es la reducción de la dimensión espacial, lo que disminuye la cantidad de datos y acelera el procesamiento. Al conservar sólo los valores más altos, resalta las características más relevantes, haciendo que el modelo se enfoque en patrones fuertes. También ayuda a reducir el riesgo de sobreajuste, al eliminar información redundante o poco significativa. Otra ventaja es que introduce invarianza ante pequeñas traslaciones, permitiendo que el modelo sea más robusto frente a cambios sutiles en la posición de los objetos. Además, mejora la eficiencia computacional al requerir menos recursos.
Limitaciones del Max Pooling
A pesar de sus beneficios, el max pooling presenta limitaciones importantes. Una de las principales limitaciones es la pérdida de información, ya que al conservar sólo el valor máximo dentro de una región, se descartan todos los demás datos, incluso si son relevantes. Esto puede afectar la precisión en tareas que requieren detalles finos. Además, al ser una operación fija y no aprendida, no se adapta al contenido específico de la imagen como lo haría una capa entrenable. El uso excesivo de pooling también puede llevar a una representación demasiado simplificada. Otra limitación es que no capta relaciones especiales entre características dentro de la ventana.
Variantes y Mejoras del Max Pooling
Existen varias variantes y mejoras del max pooling que buscan superar sus limitaciones y adaptarse mejor a diferentes contextos. Una de ellas es el global max pooling, que reduce todo el mapa de características a un solo valor máximo, útil para tareas de clasificación global. También está el stochastic pooling, que elige un valor al azar dentro de la ventana según una distribución basada en la magnitud de los valores, introduciendo aleatoriedad útil para evitar el sobreajuste. Otra variante es el spatial pyramid pooling, que permite trabajar con entradas de distintos tamaños sin necesidad de redimensionar. Además, algunos modelos combinan max y average pooling para aprovechar lo mejor de ambos métodos. Se han propuesto también técnicas de pooling aprendible, donde la red ajusta cómo combinar los valores.
Futuro del Max Pooling en la IA
El futuro del max pooling en la inteligencia artificial apunta hacia una evolución más flexible y adaptativa. Aunque sigue siendo una técnica eficiente y ampliamente usada, nuevos enfoques buscan superar sus limitaciones, como la pérdida de información. Se espera que aumente el uso de variantes como el pooling aprendible, donde los modelos ajustan dinámicamente cómo resumir las características. Además, con el avance de arquitecturas como Vision Transformers, algunas tareas están comenzando a prescindir del pooling tradicional. Aun así, el max pooling continuará siendo útil en modelos ligeros y aplicaciones con recursos limitados. También podrían integrarse métodos híbridos que combinen pooling con atención o convoluciones dilatadas.





