Introducción
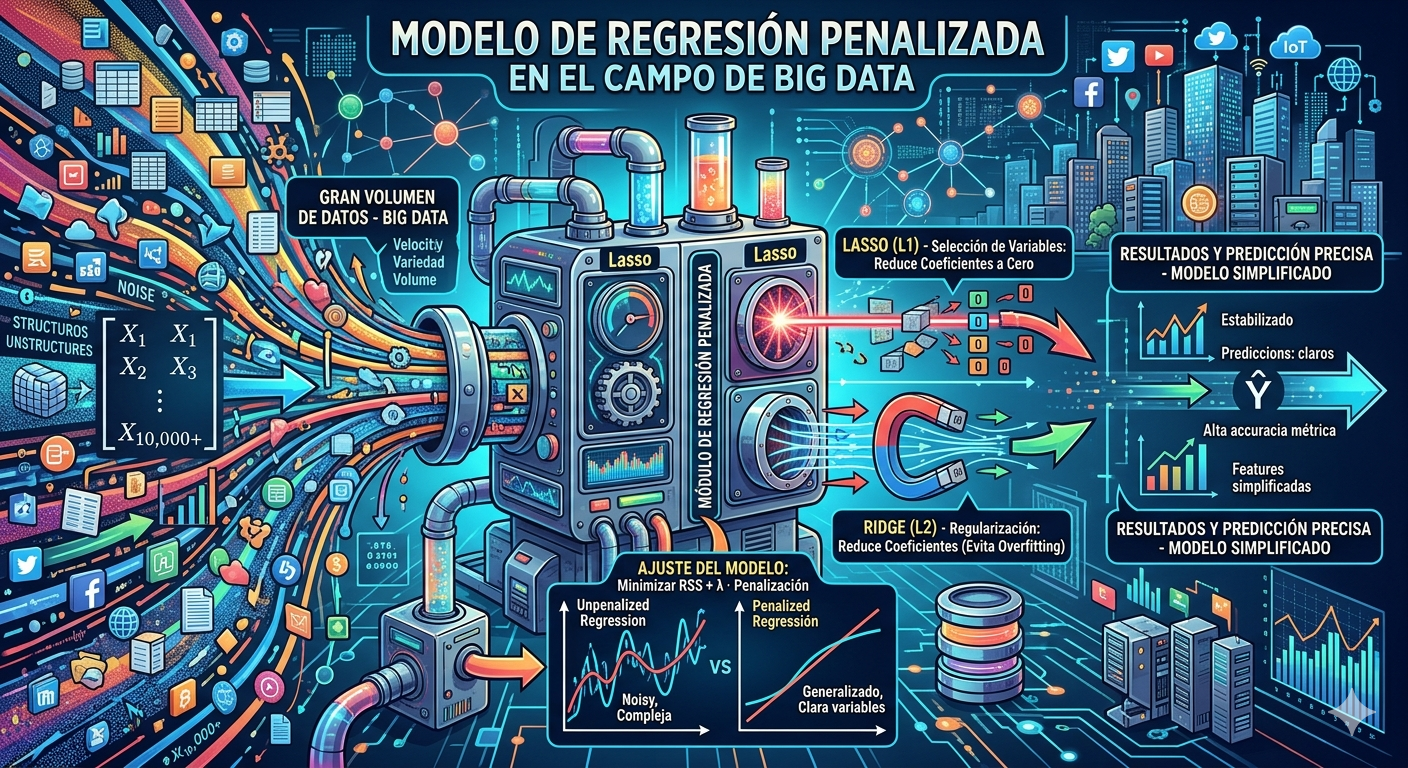
En la actualidad, el crecimiento exponencial de los datos ha transformado la manera en que las organizaciones toman decisiones. El análisis de grandes volúmenes de información requiere modelos estadísticos capaces de manejar miles o incluso millones de variables sin perder precisión ni eficiencia. En este contexto, los modelos de regresión penalizada se han convertido en una herramienta fundamental dentro del ecosistema de Big Data.
Estos modelos permiten mejorar la capacidad predictiva de los algoritmos, reducir el sobreajuste y seleccionar automáticamente las variables más relevantes. Gracias a ello, son ampliamente utilizados en áreas como inteligencia artificial, finanzas, salud, marketing digital y analítica avanzada.
¿Qué es una regresión penalizada?
La regresión penalizada es una extensión de los modelos clásicos de regresión lineal. Su principal objetivo es evitar el problema del overfitting o sobreajuste, que ocurre cuando un modelo aprende demasiado bien los datos de entrenamiento y pierde capacidad para generalizar nuevos datos.
Para lograrlo, estos métodos incorporan una penalización matemática sobre los coeficientes del modelo. Esta penalización reduce la complejidad del algoritmo y mejora su estabilidad cuando existen muchas variables o alta correlación entre ellas.
En términos simples, la regresión penalizada busca encontrar un equilibrio entre:
- Ajustar correctamente los datos.
- Mantener un modelo simple y generalizable.
Importancia de la regresión penalizada en Big Data
Los entornos de Big Data presentan desafíos específicos:
- Grandes volúmenes de información.
- Datos de alta dimensionalidad.
- Variables redundantes.
- Problemas de multicolinealidad.
- Procesamiento en tiempo real.
Los modelos tradicionales suelen perder eficiencia ante estos escenarios. En cambio, las técnicas penalizadas ofrecen ventajas importantes:
1. Reducción del sobreajuste
La penalización evita que el modelo dependa excesivamente de ciertas variables.
2. Selección automática de variables
Algunas técnicas eliminan variables irrelevantes automáticamente, reduciendo la complejidad computacional.
3. Mayor interpretabilidad
Los modelos resultan más fáciles de analizar y explicar.
4. Mejor rendimiento predictivo
La generalización mejora significativamente en conjuntos de datos masivos.
Principales modelos de regresión penalizada
Regresión Ridge
La regresión Ridge agrega una penalización basada en la suma de los cuadrados de los coeficientes.
Características principales:
- Reduce coeficientes grandes.
- Maneja bien la multicolinealidad.
- Conserva todas las variables del modelo.
Aplicaciones:
- Predicción financiera.
- Sistemas de recomendación.
- Modelos económicos.
La técnica Ridge es especialmente útil cuando existen muchas variables correlacionadas entre sí.
Regresión Lasso
La regresión Lasso incorpora una penalización basada en el valor absoluto de los coeficientes.
Ventajas:
- Puede reducir coeficientes exactamente a cero.
- Realiza selección automática de variables.
- Genera modelos más simples e interpretables.
Aplicaciones:
- Bioinformática.
- Análisis genómico.
- Detección de fraude.
- Marketing predictivo.
Lasso es muy utilizada en Big Data porque reduce considerablemente la dimensionalidad de los datos.
Elastic Net
Elastic Net combina las ventajas de Ridge y Lasso.
Beneficios:
- Selecciona variables relevantes.
- Maneja variables altamente correlacionadas.
- Mantiene estabilidad predictiva.
Casos de uso:
- Machine Learning.
- Procesamiento de lenguaje natural.
- Sistemas de clasificación masiva.
Esta técnica es ideal cuando el conjunto de datos contiene una gran cantidad de variables relacionadas.
Aplicaciones reales en Big Data
Sector financiero
Las entidades bancarias utilizan regresión penalizada para:
- Evaluar riesgo crediticio.
- Detectar fraudes.
- Predecir comportamiento de clientes.
Los modelos permiten analizar millones de transacciones en tiempo real.
Salud y medicina
En el ámbito médico, estas técnicas ayudan a:
- Analizar datos genómicos.
- Predecir enfermedades.
- Personalizar tratamientos.
La capacidad de seleccionar variables relevantes resulta clave en investigaciones clínicas.
Marketing digital
Las empresas utilizan modelos penalizados para:
- Segmentar audiencias.
- Predecir abandono de clientes.
- Optimizar campañas publicitarias.
Gracias al Big Data, las marcas pueden procesar información de redes sociales, navegación web y consumo digital.
Inteligencia artificial
Muchos algoritmos de aprendizaje automático integran técnicas de penalización para mejorar precisión y estabilidad.
Son especialmente útiles en:
- Deep Learning.
- Procesamiento de imágenes.
- Sistemas de recomendación.
Ventajas y limitaciones
Ventajas
- Mejoran la precisión predictiva.
- Reducen el riesgo de sobreajuste.
- Funcionan bien con grandes volúmenes de datos.
- Facilitan la selección de variables.
Limitaciones
- Requieren ajuste de hiperparámetros.
- Pueden aumentar el costo computacional.
- La interpretación matemática puede ser compleja.
Herramientas utilizadas
Actualmente existen múltiples herramientas para implementar regresión penalizada:
- Python con Scikit-learn.
- R y glmnet.
- Apache Spark MLlib.
- TensorFlow.
- SAS y MATLAB.
Estas plataformas permiten trabajar eficientemente con arquitecturas de Big Data.
Conclusión
Los modelos de regresión penalizada representan una solución esencial para enfrentar los desafíos analíticos del Big Data. Su capacidad para reducir el sobreajuste, seleccionar variables relevantes y mejorar la precisión predictiva los convierte en herramientas indispensables para científicos de datos y analistas.
A medida que el volumen de información continúa creciendo, estas técnicas seguirán desempeñando un papel clave en el desarrollo de modelos de inteligencia artificial y analítica avanzada. Comprender su funcionamiento no solo es importante desde una perspectiva académica, sino también profesional, ya que forman parte del núcleo de muchas aplicaciones modernas basadas en datos.





